AWK is a cross-platform programming language designed for Linux/Unix by Alfred Aho, Peter Weinberger, and Brian Kernighan. However, unlike any common Linux command, it is a complete text-processing engine. AWK was built for text processing and is typically used for data extraction and reporting, and still can be used for that. To understand the basic usage of AWK, in this tutorial (article), we will go through the different examples explaining the common commands to use by AWK for processing, extracting data, and pattern scanning. It’s often used for extracting and reporting data from files, based on patterns you define.
Why Use AWK?
The command scenarios of AWK usage are to process text files, extract parts of the data, and perform actions on that data. AWK is useful for CSV or tabulated data where we need to filter and manipulate the text but do not want to write extensive codes instead, it is a one-liner script that can filter and manipulate text.
Basic Syntax of AWK
The basic syntax of an AWK command is:
awk options 'selection _criteria {action}' input-file- options: Additional parameters to use with AWK command to get desired results- To get the list of options one can simply type ‘awk’ and hit the Enter key.
- selection_criteria: Determines which records (lines) are affected.
- action: Specifies what to do with the selected records.
- input-file: The file on which AWK will operate
AWK Examples to Get You Started
We have performed all these AWK command examples on Ubuntu however it will be same for other linux such as RedHat, CentOS, Fedora, Debian etc.
Example 1: AWK to Print All Lines
Using the AWK command, if we want to print all the lines of a file on the terminal, we can use that in the following way:
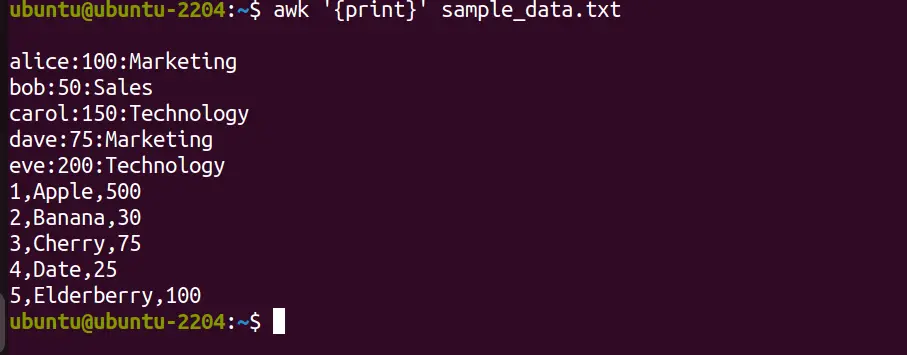
awk '{print}' sample_data.txtThis command tells AWK to execute the print action on every line of “sample_data.txt”. Note: Don’t forget to replace the “sample_data.txt” with the actual file name you want to use.
Example 2: Print Specific Fields
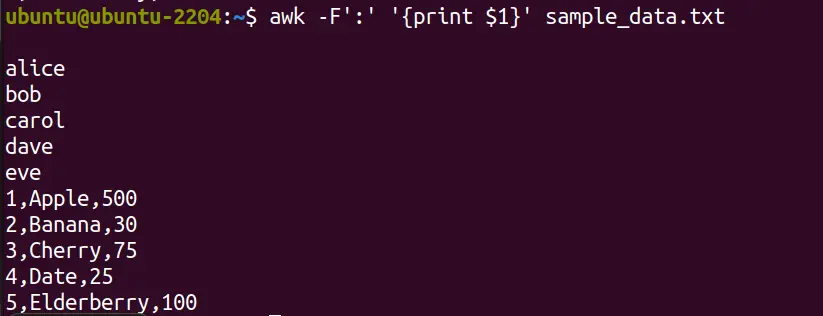
In another example, we want AWK to give a file and want the output to list the details or data of a specific with lines in the format username:userid:groupid:info, you can print just the usernames (first field) with:
awk -F':' '{print $1}' sample_data.txtHere, -F’:’ tells AWK to use “:” as the field separator, and “$1” refers to the first field. Now, as we have asked the command to use “:” as a separator, hence in the output, it has given the values of the first column.
Example 3: Summing Up Numbers
If you have a file that contains a list of numbers, you can sum them up with:
awk '{sum += $1} END {print sum}' sample_data.txtThis script adds each number available in the first column ($1) to a running total (sum) and prints the total after processing all lines.

Example 4: Filtering Text using AWK
Now, we want the AWK to filter the text or numbers available in a file. To do that, we use the given command in which we are asking “AWK” to filter and print the lines of numbers greater than “1” and in the second command we want to print only the numbers that are greater than “50”. The same can be done for text as well.
awk '$1 > 1' numbers.txt
awk '$1 > 50' numbers.txt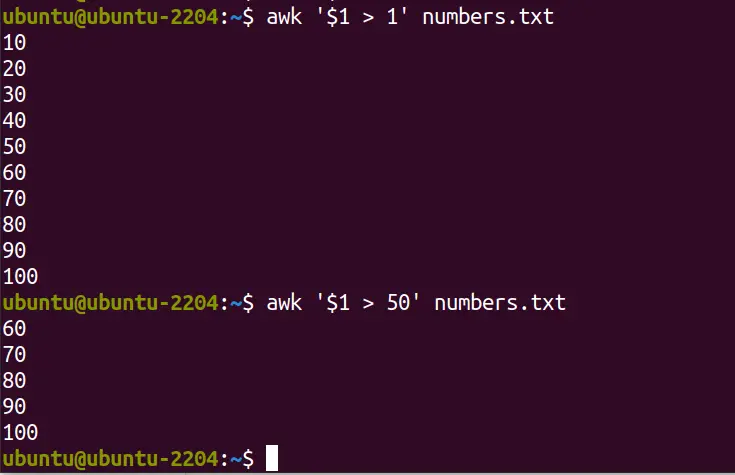
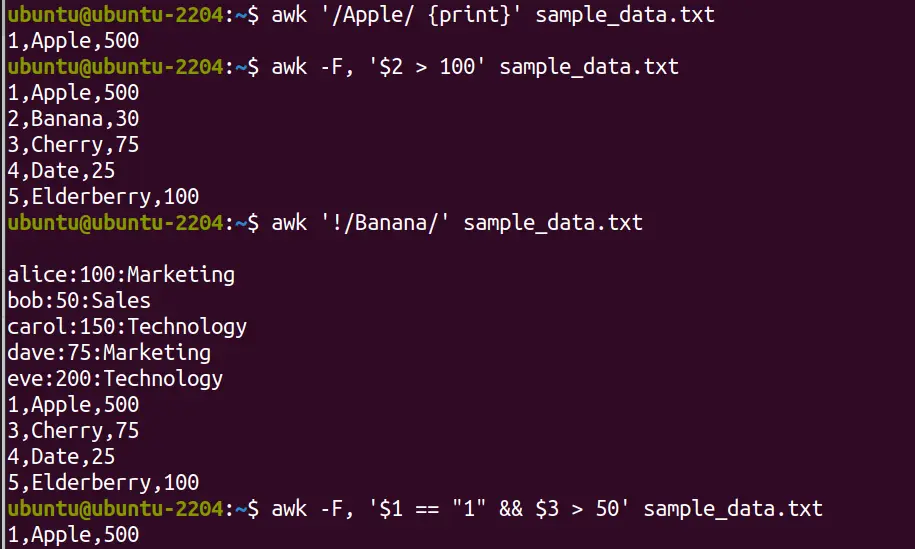
Similarly, if you want to print all rows that contain the word “Apple”:
awk '/Apple/ {print}' sample_data.txtTo exclude some text and then print all rows, let’s say we want to print all data that do not contain the word “Banana”:
awk '!/Banana/' file.txtNow, if we want to print rows where the first column is “1 and the third column ($3) which is greater than 50.
awk -F, '$1 == "1" && $3 > 50' file.txtIn the screenshot, we didn’t have any value greater than 50 in the third column, hence only the value for the first expression is satisfied.
We can also further filter the text using “AWK” and also manipulate the data while printing. For example, if we want to print the first and the data corresponding to them in the third column row of our file; where the first column must be less than 50, and also change the field separator to a semicolon.

Example 5: Formatting Output
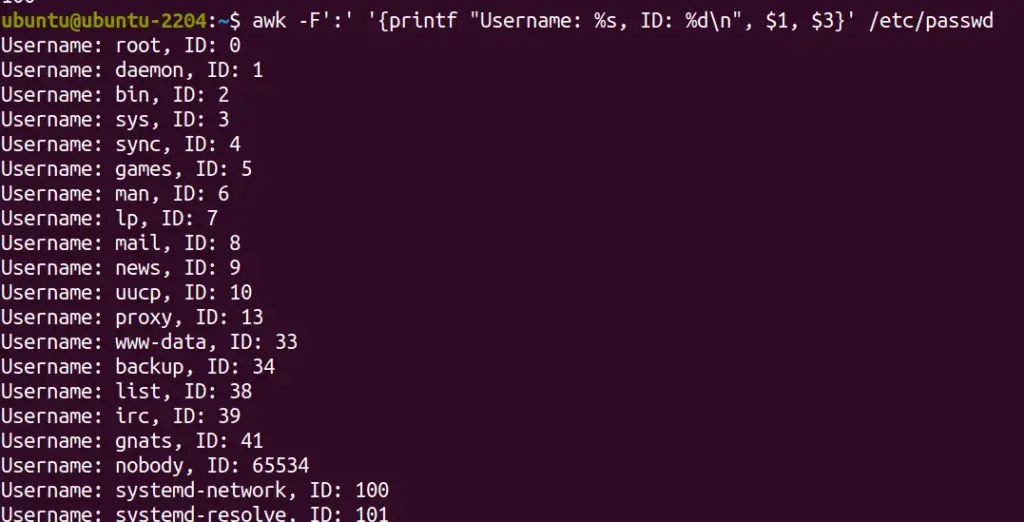
We can also use AWK language to tell the system to print the output in an organized format. For example, to print a list of usernames and their corresponding user IDs in a custom format:
awk -F':' '{printf "Username: %s, ID: %d\n", $1, $3}' /etc/passwdThis command uses printf for formatted output, displaying the username and ID in a more readable form.
Example 6: Counting Lines
Suppose you have a long list of numbers or lines in the file but don’t know how many lines are there, hence counting the number of lines in a file and quickly assessing the size of a dataset, here is the syntax to use:
awk 'END {print NR}' sample_data.txtThe “NR” option in the above command keeps track of the number of records (lines) processed.

Example 7: Sum and Average with AWK
Calculate the sum and average of numbers in a single column. For example, we have two files one is “Sample_data.txt” and “numbers.txt“, now to sum the numbers available in the first column and get the average of them, we use the given syntax:
awk '{sum += $1; count++} END {print "Sum: ", sum, "Average: ", sum/count}' numbers.txtThis script accumulates the sum of the scores and counts the entries to calculate the average at the end.

Example 8: Modifying Field Separator
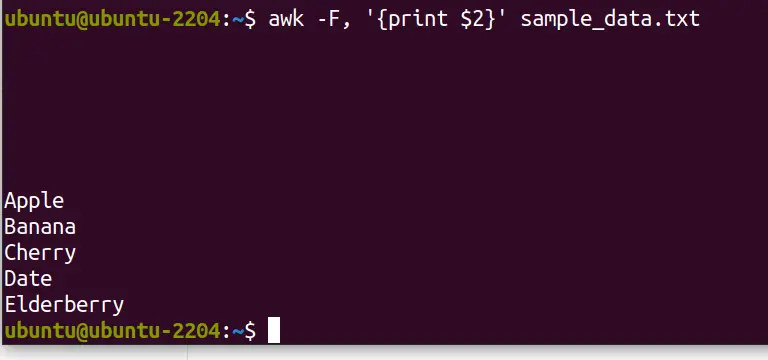
By default, AWK uses whitespace as the field separator. You can change this to parse CSV or text files or files with custom delimiters. For instance, to process a file and print the second column:
awk -F, '{print $2}' sample_data.txt “-F,” sets the field separator to a comma, making it easy to work with CSV files.
Example 9: Displaying Line Numbers with Text
If you want to print out each line in file preceded by its line number, you can use the AWK command in the following way:
awk '{print NR, $0}' file.txt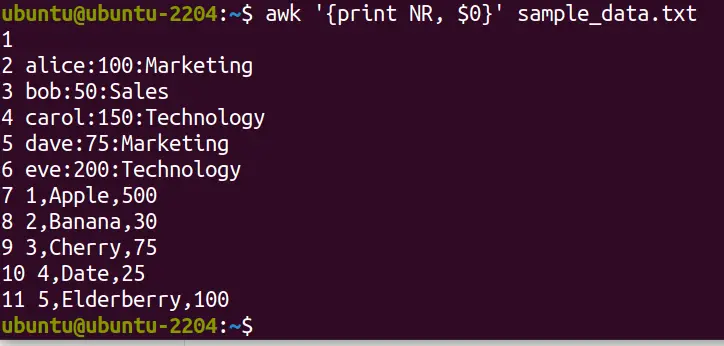
NR is AWK’s built-in variable that keeps track of the number of records (lines) processed whereas the “$0” represents the entire current line. The command prints the line number (NR), followed by the original line content ($0) for each line in file.txt.
Script Example – Calculate the number of lines (records) for each column or rows
If you want to calculate the rows and columns, consider using the AWK command line tool with a script. However, one should know the current structure of the file data before calculating columns or rows. So, a general approach to count non-empty fields in each column across all rows might look like this:
awk -F, '{for(i=1; i<=NF; i++) if($i != "") colCount[i]++} END{for(i in colCount) print "Column " i " has " colCount[i] " non-empty lines"}' sample_data.txt
Similarly, we can use the above command for counting non-empty rows as well:
awk -F, '{validRow=1; for(i=1; i<=NF; i++) if($i == "") validRow=0} validRow{validRowCount++} END{print "Total non-empty rows across all columns: " validRowCount}' sample_data.txt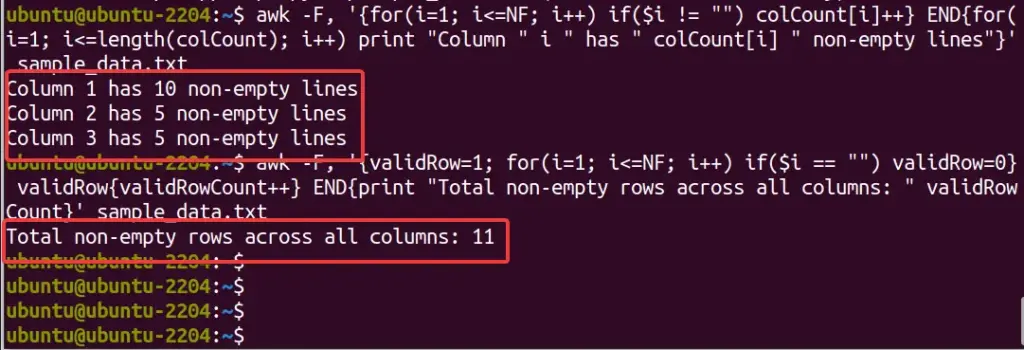
This script does the following:
-F,sets the field separator to a comma, which you can change based on your file’s delimiter.NFis an AWK built-in variable that holds the number of fields (columns) in the current record.colCount[i]++increments a count for each columniif the field is not empty.- The
ENDblock iterates over thecolCountarray, printing the number of non-empty lines for each column. - We have also used a flag
validRowfor each row, assuming the row is valid initially. - If any field is empty, it is set
validRowto 0. - If
validRowremains 1 (indicating that all fields in the row had some value), it incrementsvalidRowCount.
So, these were few examples on how to use AWK domain-specific programming language to format text, sum or filter data. You can know about it further from the AWK man page or User guide.